🧠 神经元 (Neuron) - 交互式
拖动滑块,看看一个神经元的输出是如何计算出来的!
激活后输出 (Sigmoid): 0.55
LAYER-CAKE 层 (Layer)
一层就是一组并肩工作的神经元。一个MLP至少有三层:输入层接收原始数据,隐藏层(可以有多层)负责提取复杂的特征,输出层给出最终的预测结果。
➡️ 前向传播 (Forward Propagation)
信息从输入层开始,逐层向前传递,每一层的神经元都根据上一层的输出进行计算,直到输出层给出一个预测答案。这个过程就像一次性的"猜测"。
⬅️ 反向传播 (Backpropagation)
网络"学习"和"纠错"的关键。在做出猜测后,网络会将其与正确答案比较,计算出"误差"。然后,这个误差信号会从后向前传播,告诉每一层的连接权重"你们应该如何微调,才能让下次的猜测更准一些"。
📝 MNIST 数据集
MNIST 是一个包含 70,000 张手写数字图像的数据集,每张图片都是 28×28 像素的灰度图像。这是机器学习领域的"Hello World"数据集,非常适合用来学习图像分类。
🎯 分类任务
我们的目标是训练一个神经网络,让它能够识别手写数字(0-9)。这是一个多分类问题,输出层需要 10 个神经元,每个神经元对应一个数字的概率。
🖼️ 图像预处理
在输入神经网络之前,我们需要将图像数据标准化(将像素值从 0-255 缩放到 0-1),这样可以加快训练速度并提高模型性能。
📊 评估指标
我们使用准确率(Accuracy)来评估模型性能,它表示正确预测的样本比例。对于 MNIST 这样的平衡数据集,准确率是一个很好的评估指标。
🧠 激活函数 (Activation Function)
激活函数决定神经元的输出是否被"激活",从而引入非线性,使神经网络能够拟合复杂的数据。常见的激活函数包括 Sigmoid、ReLU 和 Tanh。
📉 损失函数 (Loss Function)
损失函数用于衡量模型预测与真实标签之间的差距,神经网络的训练目标就是最小化它。分类任务中常用的是交叉熵损失函数(Cross-Entropy Loss)。
🚀 学习率 (Learning Rate)
学习率是控制神经网络每次参数更新幅度的超参数。学习率太大会导致不稳定,太小则训练缓慢。通常需要结合调参或使用自适应优化器。
📦 批训练 (Mini-Batch Training)
不是每次训练都用全部数据,而是分成小批量(如每批 32 张图像)训练,可以提高效率并稳定梯度,是现代深度学习的标准做法。
🔍 过拟合 (Overfitting)
当模型在训练集上表现很好,但在新数据(测试集)上效果差时,就发生了过拟合。这意味着模型学到了太多训练集的"细节",而不具备泛化能力。
🧩 正则化 (Regularization)
为了防止过拟合,我们可以对模型加入限制,比如 L2 正则化(惩罚过大的参数)或 Dropout(随机丢弃部分神经元),使模型更具泛化能力。

神经网络训练过程解析
这个动画展示了多层感知机(MLP)在训练过程中的关键步骤:
- 前向传播:输入数据从左侧进入网络,经过每一层的权重计算和激活函数处理,最终得到预测结果。
- 误差计算:将预测结果与真实标签比较,计算误差(损失函数值)。
- 反向传播:误差信号从右向左传播,计算每个参数对误差的贡献。
- 参数更新:根据误差信号调整网络中的权重和偏置,使预测更接近真实值。
动画中可以看到:
- 数据流动的方向(前向传播和反向传播)
- 每层神经元的激活状态(颜色深浅表示激活程度)
- 权重更新的过程(线条粗细变化)
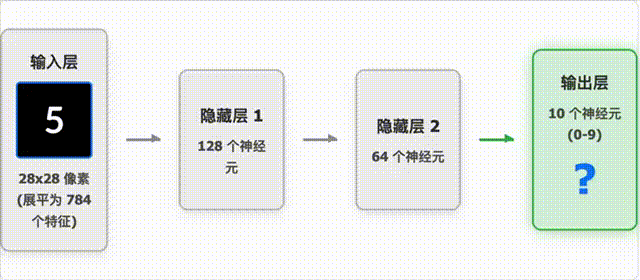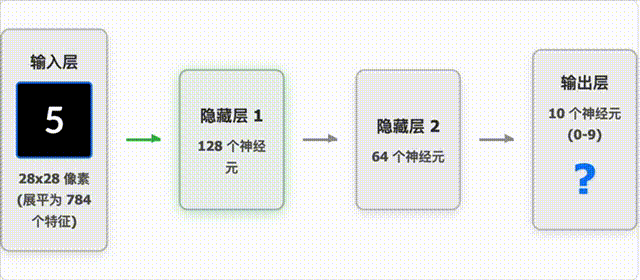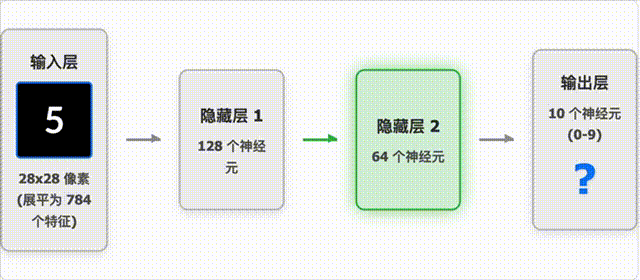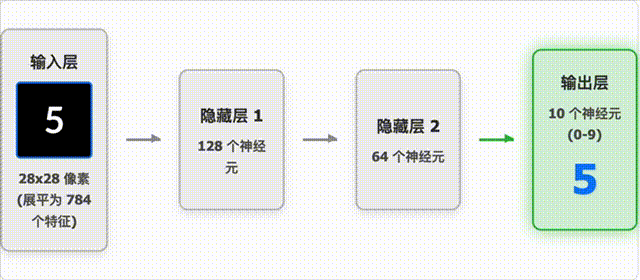
手写数字识别过程
这个动画展示了神经网络如何识别手写数字:
- 图像预处理:将手写数字图像转换为 28×28 像素的灰度图,并进行标准化处理。
- 特征提取:神经网络自动学习图像中的关键特征,如笔画、曲线等。
- 分类决策:根据提取的特征,网络输出每个数字(0-9)的概率分布。
- 结果输出:选择概率最高的数字作为最终预测结果。
动画中展示了:
- 输入图像的处理过程
- 网络各层的激活模式
- 最终预测结果及其置信度
通过修改下方代码,尝试完成以下挑战,观察模型准确率的变化!
- 任务一:调整隐藏层的大小或层数(如
hidden_layer_sizes=(128,)改为(256,128)),看看模型是否学得更好或更快? - 任务二:更换激活函数(添加
activation='tanh'或'relu'到MLPClassifier中),哪个函数带来更高的准确率? - 任务三:修改
max_iter、batch_size和learning_rate_init参数,探索训练速度与最终效果之间的平衡。
代码编辑区域
模拟训练MNIST流程详解
-
导入所需工具
- 使用
numpy生成随机数据。 - 从
sklearn.neural_network引入MLPClassifier构建神经网络模型。 StandardScaler用于对输入数据进行标准化处理。train_test_split用于将数据拆分为训练集和测试集。time用于记录模型训练耗时。
- 使用
-
生成模拟数据
- 使用
np.random.rand()生成 1000 行,每行 784 个特征(模拟 28x28 像素图像)。 - 使用
np.random.randint()随机生成对应的标签(0 到 9 之间的整数,模拟手写数字)。 - 使用
StandardScaler将数据标准化,使每个特征均值为 0,方差为 1,有助于加速训练。
- 使用
-
拆分训练集和测试集
- 使用
train_test_split()将 1000 个样本按 8:2 分成训练集和测试集。 - 这样可以确保模型在训练时看不到测试数据,从而更客观地评估其性能。
- 使用
-
构建神经网络模型
- 使用
MLPClassifier构建一个具有单隐藏层的多层感知机神经网络。 hidden_layer_sizes=(128,)表示隐藏层包含 128 个神经元。max_iter=20表示最多训练 20 次(epoch)。early_stopping=True会在验证集上连续 5 次性能不提升时提前终止训练。validation_fraction=0.1意味着从训练集中划出 10% 作为验证集用于早停。
- 使用
-
开始训练模型
- 通过
model.fit(X_train, y_train)启动训练过程。 - 模型会自动通过反向传播算法调整参数,逐步提升预测准确率。
- 训练前后使用
time.time()记录并计算耗时。
- 通过
-
在训练集和测试集上评估模型效果
- 使用
model.score()分别计算训练集和测试集的准确率。 - 高训练准确率说明模型已学会当前数据,测试准确率更能反映泛化能力。
- 使用
-
输出训练结果
- 训练完成后,输出训练耗时、训练准确率和测试准确率。
- 最终提示用户模型可以用于可视化页面进行预测。
模型状态
状态: 未训练
最终准确率: N/A
使用说明
- 首先切换到 "动手实验" 标签页
- 点击 "运行代码" 按钮训练模型
- 等待训练完成后,返回此页面
- 现在你可以在画布上画数字或上传图片进行预测了!
预测结果
上传图片
支持上传手写数字图片(JPG、PNG格式)